Advancing Data Privacy: A Novel K-Anonymity Algorithm with Dissimilarity Tree-Based Clustering and Minimal Information Loss
Article Sidebar
Main Article Content
Abstract
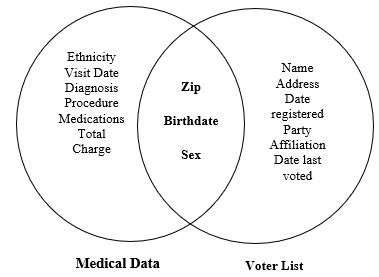
Anonymization serves as a crucial privacy protection technique employed across various technology domains, including cloud storage, machine learning, data mining and big data to safeguard sensitive information from unauthorized third-party access. As the significance and volume of data grow exponentially, comprehensive data protection against all threats is of utmost importance. The main objective of this paper is to provide a brief summary of techniques for data anonymization and differential privacy.A new k-anonymity method, which deviates from conventional k-anonymity approaches, is proposed by us to address privacy protection concerns. Our paper presents a new algorithm designed to achieve k-anonymity through more efficient clustering. The processing of data by most clustering algorithms requires substantial computation. However, by identifying initial centers that align with the data structure, a superior cluster arrangement can be obtained.Our study presents a Dissimilarity Tree-based strategy for selecting optimal starting centroids and generating more accurate clusters with reduced computing time and Normalised Certainty Penalty (NCP). This method also has the added benefit of reducing the Normalised Certainty Penalty (NCP). When compared to other methods, the graphical performance analysis shows that this one reduces the amount of overall information lost in the dataset being anonymized by around 20% on average. In addition, the method that we have designed is capable of properly handling both numerical and category characteristics.
Article Details
References
Rizwan M, Shabbir A, Javed AR, Srivastava G, Gadekallu TR, Shabir M, et al. Risk monitoring strategy for confidentiality of healthcare information. Comput Electr Eng. (2022) 100:107833. doi: 10.1016/j.compeleceng.2022.107833
El Zarif O, Haraty RA. Toward information preservation in healthcare systems. Innov Heal Informat A Smart Healthc Prim. (2020) 163–85. doi: 10.1016/B978-0-12-819043-2.00007-1
Andrew J, Karthikeyan J, Jebastin J. Privacy preserving big data publication on cloud using mondrian anonymization techniques and deep neural networks. In: 2019 5th International Conference on Advanced Computing and Communication Systems. (2019). p. 722–7.
Dhasarathan C, Hasan MK, Islam S, Abdullah S, Mokhtar UA, Javed AR, et al. COVID-19 health data analysis and personal data preserving: a homomorphic privacy enforcement approach. Comput Commun. (2023) 199:87–97. doi: 10.1016/j.comcom.2022.12.004
Haraty RA, Boukhari B, Kaddoura S. An effective hash-based assessment and recovery algorithm for healthcare systems. Arab J Sci Eng. (2022) 47:1523–36. doi: 10.1007/s13369-021-06009-4
Liu YN, Wang YP, Wang XF, Xia Z, Xu JF. Privacy-preserving raw data collection without a trusted authority for IoT. Comput Networks. (2019) 148:340–8. doi: 10.1016/j.comnet.2018.11.028
Tiancheng Li, Ninghui Li, Senior Member, IEEE, Jia Zhang, Member, IEEE, and Ian Molloy “Slicing: A New Approach for Privacy Preserving Data Publishing” Proc. IEEE Transactions On Knowledge and Data Engineering, Vol. 24, No. 3, March 2012.
Sampurnanand Dwivedi, Vipul Singhal. (2023). A Study of Responsive Image Denoising Algorithm . International Journal of Intelligent Systems and Applications in Engineering, 11(3s), 286–291. Retrieved from https://ijisae.org/index.php/IJISAE/article/view/2686
V. Ciriani, S. De Capitani di Vimercati, S. Foresti, and P. Samarati On K-Anonymity. In Springer US, Advances in Information Security (2007).
Latanya Sweeney. k-anonymity: a model for protecting privacy. International Journal on Uncertainty, Fuzziness and Knowledge-Based Systems, 10(5):557–570, 2002.[1] Swagatika Devi, K-ANONYMITY: The History of an IDEA International Journal of Soft Computing and Engineering (IJSCE) ISSN: 2231-2307, Volume-2, Issue-1, March 2011.
Daries, J. P., Reich, J., Waldo, J., Young, E. M., Whittinghill, J., Ho, A.D., Seaton, D. T., Chuang, I. Privacy, anonymity, and big data in the social sciences. Communications of the ACM 57(9): 56-63,2014.
Angiuli, O., Blitzstein, J., and Waldo, J. How to de-identify your data. Queue 13, 8 Sept. 2015.
G.Ghinita, Y. Tao, and P. Kalnis, “On the Anonymization of Sparse High-Dimensional Data,” Proc. IEEE 24th Int’l Conf. Data Eng. (ICDE), pp. 715-724, 2008.
Ghinita, Member IEEE, Panos Kalnis, Yufei Tao,” Anonymous Publication of Sensitive Transactional Data” in Proc. Of IEEE Transactions on Knowledge and Data Engineering February 2011 (vol. 23 no. 2) pp. 161-174.
Ana Oliveira, Yosef Ben-David, Susan Smit, Elena Popova, Milica Mili?. Improving Decision Quality through Machine Learning Techniques. Kuwait Journal of Machine Learning, 2(3). Retrieved from http://kuwaitjournals.com/index.php/kjml/article/view/202
Zhao FeiFei, Dong LiFeng, Wang Kun, Li Yang, Study on Privacy Protection Algorithm Based on K-Anonymity, Physics Procedia, Volume 33, ISSN 1875-3892, 2012
Samarati, Pierangela; Sweeney, Latanya, “Protecting privacy when disclosing information: k-anonymity and its enforcement through generalization and suppression.” Carnegie Mellon University. Journal contribution, 2018.
Sweeney L, k-anonymity: a model for protecting privacy. Int J Uncertain Fuzzy Knowledge Based System 10 (5):557–570,2002.
Meyerson A, Williams R, On the complexity of optimal k-anonymity. In: PODS ’04: proceedings of the twenty-third ACM SIGMOD-SIGACT-SIGART symposium on principles of database systems, pp 223–228,2004.
Mr. Rahul Sharma. (2013). Modified Golomb-Rice Algorithm for Color Image Compression. International Journal of New Practices in Management and Engineering, 2(01), 17 - 21. Retrieved from http://ijnpme.org/index.php/IJNPME/article/view/13
Li, N., Qardaji, W. H., & Su, D. Provably private data anonymization: Or, k-anonymity meets differential privacy. 2011.
Dankar, F. K., & El Emam, K. (2012, March). The application of differential privacy to health data. In Proceedings of the 2012 Joint EDBT/ICDT Workshops (pp. 158-166). ACM.
Friedman, A., & Schuster, A. (2010, July). Data mining with differential privacy. In Proceedings of the 16th ACM SIGKDD international conference on Knowledge discovery and data mining (pp. 493-502). ACM
Simi, Ms & Nayaki, K & Elayidom, An Extensive Study on Data Anonymization Algorithms Based on K-Anonymity. IOP Conference Series: Materials Science and Engineering. 225. 012279. 10.1088/1757-899X/225/1/012279,2017
Isabella Rossi, Reinforcement Learning for Resource Allocation in Cloud Computing , Machine Learning Applications Conference Proceedings, Vol 1 2021.
Feng Bo, Hao Wenning, Chen Gang, Jin Dawei, Zhao Shuining, “An Improved PAM Algorithm for Optimizing Initial Cluster Centre,” IEEE, 2012, 978-1-4673-2008- 5/12.