A Study of Techniques and Challenges in Text Recognition Systems
Article Sidebar
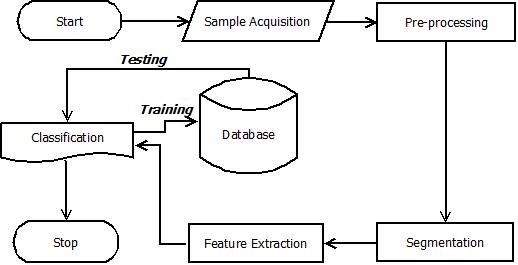
Main Article Content
Abstract
The core system for Natural Language Processing (NLP) and digitalization is Text Recognition. These systems are critical in bridging the gaps in digitization produced by non-editable documents, as well as contributing to finance, health care, machine translation, digital libraries, and a variety of other fields. In addition, as a result of the pandemic, the amount of digital information in the education sector has increased, necessitating the deployment of text recognition systems to deal with it. Text Recognition systems worked on three different categories of text: (a) Machine Printed, (b) Offline Handwritten, and (c) Online Handwritten Texts. The major goal of this research is to examine the process of typewritten text recognition systems. The availability of historical documents and other traditional materials in many types of texts is another major challenge for convergence. Despite the fact that this research examines a variety of languages, the Gurmukhi language receives the most focus. This paper shows an analysis of all prior text recognition algorithms for the Gurmukhi language. In addition, work on degraded texts in various languages is evaluated based on accuracy and F-measure.
Article Details
References
Y. Manchala, J. Kinthali, K. Kotha, K. S. Kumar, and J. Jayalaxmi, “Handwritten Text Recognition using Deep Learning with TensorFlow,” Int. J. Eng. Res., vol. V9, no. 05, pp. 594–600, 2020, doi: 10.17577/ijertv9is050534.
S. IMPEDOVO, L. OTTAVIANO, and S. OCCHINEGRO, “OPTICAL CHARACTER RECOGNITION — A SURVEY,” Int. J. Pattern Recognit. Artif. Intell., vol. 05, no. 01n02, pp. 1–24, Jun. 1991, doi: 10.1142/S0218001491000041.
V. . Govindan and A. . Shivaprasad, “Character recognition — A review,” Pattern Recognit., vol. 23, no. 7, pp. 671–683, Jan. 1990, doi: 10.1016/0031-3203(90)90091-X.
N. Arica and F. T. Yarman-Vural, “Optical character recognition for cursive handwriting,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 24, no. 6, pp. 801–813, Jun. 2002, doi: 10.1109/TPAMI.2002.1008386.
N. Islam, Z. Islam, and N. Noor, “A Survey on Optical Character Recognition System,” J. Inf. Commun. Technol., vol. 10, no. 2, pp. 1–7, Oct. 2017, [Online]. Available: http://arxiv.org/abs/1710.05703.
K. Dutta, P. Krishnan, M. Mathew, and C. V. Jawahar, “Improving CNN-RNN Hybrid Networks for Handwriting Recognition,” in 2018 16th International Conference on Frontiers in Handwriting Recognition (ICFHR), Aug. 2018, pp. 80–85, doi: 10.1109/ICFHR-2018.2018.00023.
J. Memon, M. Sami, R. A. Khan, and M. Uddin, “Handwritten Optical Character Recognition (OCR): A Comprehensive Systematic Literature Review (SLR),” IEEE Access, vol. 8, pp. 142642–142668, 2020, doi: 10.1109/ACCESS.2020.3012542.
N. Sankaran and C. V Jawahar, “Recognition of printed Devanagari text using BLSTM Neural Network,” in Proceedings of the 21st International Conference on Pattern Recognition (ICPR2012), 2012, pp. 1–7.
A. Ray, S. Rajeswar, and S. Chaudhury, “Text recognition using deep BLSTM networks,” in 2015 Eighth International Conference on Advances in Pattern Recognition (ICAPR), Jan. 2015, pp. 1–6, doi: 10.1109/ICAPR.2015.7050699.
M. Z. Alom, P. Sidike, T. M. Taha, and V. K. Asari, “Handwritten Bangla Digit Recognition Using Deep Learning,” Comput. Vis. Pattern Recognit., pp. 1–9, May 2017, [Online]. Available: http://arxiv.org/abs/1705.02680.
B. Polaiah, N. S. S. T. Velpuri, G. K. Pandala, S. L. R. S. Polavarapu, and P. R. Kumari, “Handwritten text recognition using machine learning techniques in application of NLP.,” Int. J. Innov. Technol. Explor. Enginnering, pp. 1394–1397, 2019.
Zecheng Xie, Zenghui Sun, Lianwen Jin, Ziyong Feng, and Shuye Zhang, “Fully convolutional recurrent network for handwritten Chinese text recognition,” in 2016 23rd International Conference on Pattern Recognition (ICPR), Dec. 2016, pp. 4011–4016, doi: 10.1109/ICPR.2016.7900261.
R. Messina and J. Louradour, “Segmentation-free handwritten Chinese text recognition with LSTM-RNN,” in 2015 13th International Conference on Document Analysis and Recognition (ICDAR), Aug. 2015, pp. 171–175, doi: 10.1109/ICDAR.2015.7333746.
S. Bhowmik, R. Sarkar, B. Das, and D. Doermann, “GiB?: A ${G}$ ame Theory ${I}$ nspired ${B}$ inarization Technique for Degraded Document Images,” IEEE Trans. Image Process., vol. 28, no. 3, pp. 1443–1455, Mar. 2019, doi: 10.1109/TIP.2018.2878959.
A. Rehman and T. Saba, “Neural networks for document image preprocessing: state of the art,” Artif. Intell. Rev., vol. 42, no. 2, pp. 253–273, Aug. 2014, doi: 10.1007/s10462-012-9337-z.
N. Arica and F. T. Yarman-Vural, “An overview of character recognition focused on off-line handwriting,” IEEE Trans. Syst. Man Cybern. Part C (Applications Rev., vol. 31, no. 2, pp. 216–233, May 2001, doi: 10.1109/5326.941845.
R. G. Casey and E. Lecolinet, “A survey of methods and strategies in character segmentation,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 18, no. 7, pp. 690–706, Jul. 1996, doi: 10.1109/34.506792.
F. P. Shah and V. Patel, “A review on feature selection and feature extraction for text classification,” in 2016 International Conference on Wireless Communications, Signal Processing and Networking (WiSPNET), Mar. 2016, pp. 2264–2268, doi: 10.1109/WiSPNET.2016.7566545.
S. Ding, H. Zhu, W. Jia, and C. Su, “A survey on feature extraction for pattern recognition,” Artif. Intell. Rev., vol. 37, no. 3, pp. 169–180, Mar. 2012, doi: 10.1007/s10462-011-9225-y.
S. Pletschacher, J. Hu, and A. Antonacopoulos, “A New Framework for Recognition of Heavily Degraded Characters in Historical Typewritten Documents Based on Semi-Supervised Clustering,” in 2009 10th International Conference on Document Analysis and Recognition, 2009, pp. 506–510, doi: 10.1109/ICDAR.2009.267.
N. F. Abubacker and R. I. Gandhi, “An extended method for recognition of broken typewritten characters special reference to tamil script,” in 2011 IEEE Conference on Open Systems, Sep. 2011, pp. 214–219, doi: 10.1109/ICOS.2011.6079265.
H. Cao, R. Prasad, and P. Natarajan, “Handwritten and Typewritten Text Identification and Recognition Using Hidden Markov Models,” in 2011 International Conference on Document Analysis and Recognition, Sep. 2011, pp. 744–748, doi: 10.1109/ICDAR.2011.155.
V. Vu?kovi? and B. Arizanovi?, “Efficient character segmentation approach for machine-typed documents,” Expert Syst. Appl., vol. 80, pp. 210–231, Sep. 2017, doi: 10.1016/j.eswa.2017.03.027.
S. Kumar and P. Sharma, “Offline Handwritten & Typewritten Character Recognition using Template Matching,” Int. J. Comput. Sci. Eng. Technol., vol. 4, no. 06, pp. 818–825, 2013, [Online]. Available: http://www.ijcset.com/docs/IJCSET13-04-06-085.pdf.
S. Naz et al., “Offline cursive Urdu-Nastaliq script recognition using multidimensional recurrent neural networks,” Neurocomputing, vol. 177, pp. 228–241, Feb. 2016, doi: 10.1016/j.neucom.2015.11.030.
S. Naz, A. I. Umar, R. Ahmed, M. I. Razzak, S. F. Rashid, and F. Shafait, “Urdu Nasta’liq text recognition using implicit segmentation based on multi-dimensional long short term memory neural networks,” Springerplus, vol. 5, no. 1, p. 2010, Dec. 2016, doi: 10.1186/s40064-016-3442-4.
S. Naz et al., “Urdu Nastaliq recognition using convolutional–recursive deep learning,” Neurocomputing, vol. 243, pp. 80–87, Jun. 2017, doi: 10.1016/j.neucom.2017.02.081.
S. R. Panda and J. Tripathy, “Odia Offline Typewritten Character Recognition using Template Matching with Unicode Mapping,” in 2015 International Symposium on Advanced Computing and Communication (ISACC), Sep. 2015, pp. 109–115, doi: 10.1109/ISACC.2015.7377325.
M. Sonkusare, R. Gupta, and A. Moghe, “A Review on Handwritten Devanagari Character Recognition,” EasyChair, pp. 1–6, 2019.
S. Puri and S. P. Singh, “An efficient Devanagari character classification in printed and handwritten documents using SVM,” Procedia Comput. Sci., vol. 152, pp. 111–121, 2019, doi: 10.1016/j.procs.2019.05.033.
G. Thilagavathi, G. Lavanya, and N. K. Karthikeyan, “Tamil handwritten character recognition using artificial neural network,” Int. J. Sci. Technol. Res., vol. 8, no. 12, pp. 1611–1616, 2019.
M. S. Khorsheed, “Recognizing Cursive Typewritten Text Using Segmentation-Free System,” Sci. World J., vol. 2015, pp. 1–7, 2015, doi: 10.1155/2015/818432.
M. S. Khorsheed, “Offline recognition of omnifont Arabic text using the HMM ToolKit (HTK),” Pattern Recognit. Lett., vol. 28, no. 12, pp. 1563–1571, Sep. 2007, doi: 10.1016/j.patrec.2007.03.014.
G. Retsinas, B. Gatos, A. Antonacopoulos, G. Louloudis, and N. Stamatopoulos, “Historical Typewritten Document Recognition Using Minimal User Interaction,” in Proceedings of the 3rd International Workshop on Historical Document Imaging and Processing, Aug. 2015, pp. 31–38, doi: 10.1145/2809544.2809559.
M. K. Jindal, G. S. Lehal, and R. K. Sharma, “A Study of Touching Characters in Degraded Gurmukhi Text,” Eng. Technol., vol. 4, no. February, pp. 121–124, 2005.
P. Mangla and H. Kaur, “An end detection algorithm for segmentation of broken and touching characters in handwritten Gurumukhi word,” in Proceedings of 3rd International Conference on Reliability, Infocom Technologies and Optimization, Oct. 2014, pp. 1–4, doi: 10.1109/ICRITO.2014.7014740.
M. K. Jindal, R. K. Sharma, and G. S. Lehal, “Structural Features for Recognizing Degraded Printed Gurmukhi Script,” in Fifth International Conference on Information Technology: New Generations (itng 2008), Apr. 2008, pp. 668–673, doi: 10.1109/ITNG.2008.223.
J. S. Madan, R. Sidhu, and D. V. Sharma, “Development of a generic structural feature extraction method for printed Gurumukhi and similar scripts,” in 3rd International Conference on Computing for Sustainable Global Development (INDIACom), 2016, pp. 1–7.
M. K. Jindal, R. K. Sharma, and G. S. Lehal, “A Study of Different Kinds of Degradation in Printed Gurmukhi Script,” in 2007 International Conference on Computing: Theory and Applications (ICCTA’07), Mar. 2007, pp. 538–544, doi: 10.1109/ICCTA.2007.19.
G. S. Lehal, “Optical character recognition of Gurmukhi script using multiple classifiers,” in Proceedings of the International Workshop on Multilingual OCR - MOCR ’09, 2009, pp. 1–7, doi: 10.1145/1577802.1577810.
M. K. Jindal, G. S. Lehal, and R. K. Sharma, “Segmentation Problems and Solutions in Printed Degraded Gurmukhi Script,” Int. J. Signal Process., vol. 2, no. 4, pp. 258–267, 2008.
R. J. Shah and T. V. Ratanpara, “Challenges of broken characters in character segmentation method for Gujarati printed documents,” in 2015 International Conference on Innovations in Information, Embedded and Communication Systems (ICIIECS), Mar. 2015, pp. 1–5, doi: 10.1109/ICIIECS.2015.7193263.
A. Singh, Y. Ghasemi, H. Jeong, M. Kim, and A. Johnson, “A comparative evaluation of the wearable augmented reality-based data presentation interface and traditional methods for data entry tasks,” Int. J. Ind. Ergon., vol. 86, p. 103190, Nov. 2021, doi: 10.1016/j.ergon.2021.103190.
R. R. Ingle, Y. Fujii, T. Deselaers, J. Baccash, and A. C. Popat, “A Scalable Handwritten Text Recognition System,” in 2019 International Conference on Document Analysis and Recognition (ICDAR), Sep. 2019, pp. 17–24, doi: 10.1109/ICDAR.2019.00013.
U. Yadav, S. Verma, D. K. Xaxa, and C. Mahobiya, “A deep learning based character recognition system from multimedia document,” in 2017 Innovations in Power and Advanced Computing Technologies (i-PACT), Apr. 2017, pp. 1–7, doi: 10.1109/IPACT.2017.8245200.
Y. He, “Research on Text Detection and Recognition Based on OCR Recognition Technology,” in 2020 IEEE 3rd International Conference on Information Systems and Computer Aided Education (ICISCAE), Sep. 2020, pp. 132–140, doi: 10.1109/ICISCAE51034.2020.9236870.
Y. Weng and C. Xia, “A New Deep Learning-Based Handwritten Character Recognition System on Mobile Computing Devices,” Mob. Networks Appl., vol. 25, no. 2, pp. 402–411, Apr. 2020, doi: 10.1007/s11036-019-01243-5.
J. Pradeep, E. Srinivasan, and S. Himavathi, “Neural network based handwritten character recognition system without feature extraction,” in 2011 International Conference on Computer, Communication and Electrical Technology (ICCCET), Mar. 2011, pp. 40–44, doi: 10.1109/ICCCET.2011.5762513.
S. Garg, K. Kumar, N. Prabhakar, A. Ratan, and A. Trivedi, “Optical Character Recognition using Artificial Intelligence,” Int. J. Comput. Appl., vol. 179, no. 31, pp. 14–20, Apr. 2018, doi: 10.5120/ijca2018916390.
V. V. Mainkar, J. A. Katkar, A. B. Upade, and P. R. Pednekar, “Handwritten Character Recognition to Obtain Editable Text,” in 2020 International Conference on Electronics and Sustainable Communication Systems (ICESC), Jul. 2020, pp. 599–602, doi: 10.1109/ICESC48915.2020.9155786.
A. Mahmood and A. Srivastava, “A Novel Segmentation Technique for Urdu Type-Written Text,” in 2018 Recent Advances on Engineering, Technology and Computational Sciences (RAETCS), Feb. 2018, pp. 1–5, doi: 10.1109/RAETCS.2018.8443958.
O. Boudraa, W. K. Hidouci, and D. Michelucci, “A robust multi stage technique for image binarization of degraded historical documents,” in 2017 5th International Conference on Electrical Engineering - Boumerdes (ICEE-B), Oct. 2017, pp. 1–6, doi: 10.1109/ICEE-B.2017.8192044.
B. Ahn, J. Ryu, H. Il Koo, and N. I. Cho, “Textline detection in degraded historical document images,” EURASIP J. Image Video Process., vol. 2017, no. 1, pp. 82–90, Dec. 2017, doi: 10.1186/s13640-017-0229-7.
A. Sehad, Y. Chibani, R. Hedjam, and M. Cheriet, “Gabor filter-based texture for ancient degraded document image binarization,” Pattern Anal. Appl., vol. 22, no. 1, pp. 1–22, Feb. 2019, doi: 10.1007/s10044-018-0747-7.
U. Garain and B. B. Chaudhuri, “Segmentation of touching characters in printed devnagari and bangla scripts using fuzzy multifactorial analysis,” IEEE Trans. Syst. Man Cybern. Part C (Applications Rev., vol. 32, no. 4, pp. 449–459, Nov. 2002, doi: 10.1109/TSMCC.2002.807272.
A. M. Ceniza, T. K. B. Archival, and K. V. Bongo, “Mobile Application for Recognizing Text in Degraded Document Images Using Optical Character Recognition with Adaptive Document Image Binarization,” J. Image Graph., vol. 6, no. 1, pp. 44–47, 2018, doi: 10.18178/joig.6.1.44-47.
A. Rehman, “Offline touched cursive script segmentation based on pixel intensity analysis: Character segmentation based on pixel intensity analysis,” in 2017 Twelfth International Conference on Digital Information Management (ICDIM), Sep. 2017, pp. 324–327, doi: 10.1109/ICDIM.2017.8244641.