Feature based-Learning with Data Increasing for video Recommendation and Computing
Article Sidebar
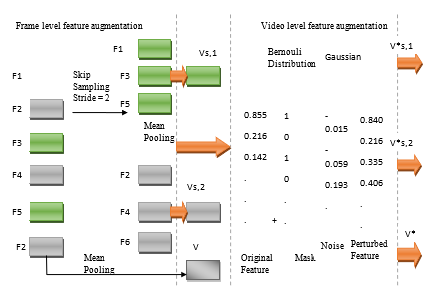
Main Article Content
Abstract
Image content analysis is crucial for determining the reliability of a link between two videos. Video characteristics are increasingly being used in image and video representation as custom pre-trained picture and video convolutional neural networks become generally available. People also have limited access to video editing tools for a variety of reasons, such as ownership and privacy concerns. You don't need to go back to the source video data to use the refined features again. An affine transformation, for instance, can be used to map a well-studied function onto an unfamiliar domain. To do this, we use a unique triplet failure in conjunction with the re-learning strategy. We propose a contemporary data augmentation method that may be applied to functionality on various frames for videos as an alternative to employing specific motion data. Extensive testing on the well-known Hulu content-based Video Relevance challenge demonstrates the process's efficacy and provides solid evidence of state-of-the-art performance.
Article Details
References
M. Liu, X. Xie, and H. Zhou, “Content-based video relevanceprediction challenge: Data, protocol, and baseline,” 2018, arXiv:1806.00737.
X. He, Z. He, J. Song, Z. Liu, Y.-G. Jiang, and T.-S. Chua, “NAIS:Neural attentive item similarity model for recommendation,” IEEE Trans. Knowl. Data Eng., vol. 30, no. 12, pp. 2354–2366, Dec. 2018.
J. Song, L. Gao, F. Nie, H. T. Shen, Y. Yan, and N. Sebe,“Optimized graph learning using partial tags and multiple features for image and video annotation,” IEEE Trans. Image Process.,vol. 25, no. 11, pp. 4999–5011, Nov. 2016.
M. Wang, R. Hong, G. Li, Z.-J. Zha, S. Yan, and T.-S. Chua, “Eventdriven web video summarization by tag localization and key-shot identification,” IEEE Trans. Multimedia, vol. 14, no. 4, pp. 975–985,Aug. 2012.
X. Liu, L. Zhao, D. Ding, and Y. Dong, “Deep hashing with categorymask for fast video retrieval,” 2017, arXiv:1712.08315.
H. Liu, H. Lu, and X. Xue, “A segmentation and graph-basedvideo sequence matching method for video copy detection,” IEEE Trans. Knowl. Data Eng., vol. 25, no. 8, pp. 1706–1718, Aug. 2013.
B. Yang, T. Mei, X.-S. Hua, L. Yang, S.-Q. Yang, and M. Li, “Onlinevideo recommendation based on multimodal fusion and relevancefeedback,” in Proc. ACM Int. Conf. Image Video Retrieval,2007, pp. 73–80.
H. Xie, S. Fang, Z.-J. Zha, Y. Yang, Y. Li, and Y. Zhang,“Convolutional attention networks for scene text recognition,” ACM Trans. Multimedia Comput. Commun. Appl., vol. 15, no. 1s, 2019,Art. no. 3.
C. Xu, X. Zhu, W. He, Y. Lu, X. He, Z. Shang, J. Wu, K. Zhang,Y. Zhang, X. Rong, Z. Zhao, L. Cai, D. Ding, and X. Li, “Fully deep learning for slit-lamp photo based nuclear cataract grading,”in Proc. Int. Conf. Med. Image Comput. Comput. Assisted Intervention,2019, pp. 513–521.
H. Xie, D. Yang, N. Sun, Z. Chen, and Y. Zhang, “Automated pulmonarynodule detection in CT images using deep convolutional neural networks,” Pattern Recognit., vol. 85, pp. 109–119, 2019.
Z. Chen, S. Ai, and C. Jia, “Structure-aware deep learning forproduct image classification,” ACM Trans. Multimedia Comput. Commun. Appl., vol. 15, no. 1s, 2019, Art. no. 4.
Annam, S. ., & Singla, A. . (2023). Estimating the Concentration of Soil Heavy Metals in Agricultural Areas from AVIRIS Hyperspectral Imagery. International Journal of Intelligent Systems and Applications in Engineering, 11(2s), 156 –. Retrieved from https://ijisae.org/index.php/IJISAE/article/view/2519
M. Wang, C. Luo, B. Ni, J. Yuan, J.Wang, and S. Yan, “First-persondaily activity recognition with manipulated object proposals and non-linear feature fusion,” IEEE Trans. Circuits Syst. Video Technol.,vol. 28, no. 10, pp. 2946–2955, Oct. 2018.
M. Larson, A. Zito, B. Loni, and P. Cremonesi, “Towards minimalnecessary data: The case for analyzing training data requirements of recommender algorithms,” in Proc. FATREC Workshop ResponsibleRecommendation, 2017, pp. 1–6.
Smith, J., Ivanov, G., Petrovi?, M., Silva, J., & García, A. Detecting Fake News: A Machine Learning Approach. Kuwait Journal of Machine Learning, 1(3). Retrieved from http://kuwaitjournals.com/index.php/kjml/article/view/142
M. Mazloom, X. Li, and C. G. Snoek, “TagBook: A semantic videorepresentation without supervision for event detection,” IEEE Trans. Multimedia, vol. 18, no. 7, pp. 1378–1388, Jul. 2016.
Y. Bhalgat, “FusedLSTM: Fusing frame-level and video-level featuresfor content-based video relevance prediction,” 2018, arXiv:1810.00136.
Muhammad Rahman, Automated Machine Learning for Model Selection and Hyperparameter Optimization , Machine Learning Applications Conference Proceedings, Vol 2 2022.
G. Kordopatis-Zilos, S. Papadopoulos, I. Patras, and Y. Kompatsiaris,“Near-duplicate video retrieval with deep metric learning,” in Proc.IEEE Int. Conf. Comput. Vis., 2017, pp. 347–356.
J. Lee and S. Abu-El-Haija, “Large-scale content-only video recommendation,”in Proc. IEEE Int. Conf. Comput. Vis. Workshop, 2017,pp. 987–995.
Y. Dong and J. Li, “Video retrieval based on deep convolutionalneural network,” in Proc. Int. Conf. Multimedia Syst. Signal Process., 2018, pp. 12–16.
J. Lee, S. Abu-El-Haija, B. Varadarajan, and A. P. Natsev,“Collaborative deep metric learning for video understanding,” in Proc. ACM SIGKDD Int. Conf. Knowl. Discovery Data Mining, 2018,pp. 481–490.
Prof. Shweta Jain. (2017). Design and Analysis of Low Power Hybrid Braun Multiplier using Ladner Fischer Adder. International Journal of New Practices in Management and Engineering, 6(03), 07 - 12. https://doi.org/10.17762/ijnpme.v6i03.59
I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley,S. Ozair, A. Courville, and Y. Bengio, “Generative adversarial nets,”in Proc. Int. Conf. Neural Inf. Process. Syst., 2014, pp. 2672–2680.
K. Sohn, H. Lee, and X. Yan, “Learning structured output representationusing deep conditional generative models,” in Proc. Int. Conf. Neural Inf. Process. Syst., 2015, pp. 3483–3491.
J. Dong, X. Li, W. Lan, Y. Huo, and C. G. M. Snoek, “Early embeddingand late reranking for video captioning,” in Proc. ACM Int. Conf. Multimedia, 2016, pp. 1082–1086.
Y. Pan, T. Mei, T. Yao, H. Li, and Y. Rui, “Jointly modeling embeddingand translation to bridge video and language,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2016, pp. 4594–4602.